Với sự phát triển mạnh mẽ của các mô hình ngôn ngữ lớn và điện toán đám mây thì việc tự xây dựng một chatbot thực sự đã trở lên rất dễ dàng. Tôi cũng đã thử tự mình xây dựng chatbot và tìm hiểu về RAG (Retrieval-Augmented Generation), qua đó giúp tôi có cơ hội thực hành, hiểu rõ các service để tạo nên một hệ thống Chatbot như AWS Bedrock, và Kendra. Trong post này tôi sẽ tóm tắt lại những nội dung gồm:
- Generative AI là gì?
- Vector DB
- Xây dựng kiến trúc RAG, ChatBot với AWS
Trước khi đi chi tiết hơn, tôi note lại một số cần chú ý khi xây dựng hệ thống RAG. Nhắc lại một chút thì hệ thống sẽ sử dụng mô hình ngôn ngữ lớn (large language model) và Generative AI.
Nếu các bạn chưa từng nghe hay biết đến Genartive AI,thì khóa học sau sẽ rất hữu ích.
Refer: genai for beginners
các bạn có thể hiểu rằng Genartive AI là một nhánh trong Deep Learning.
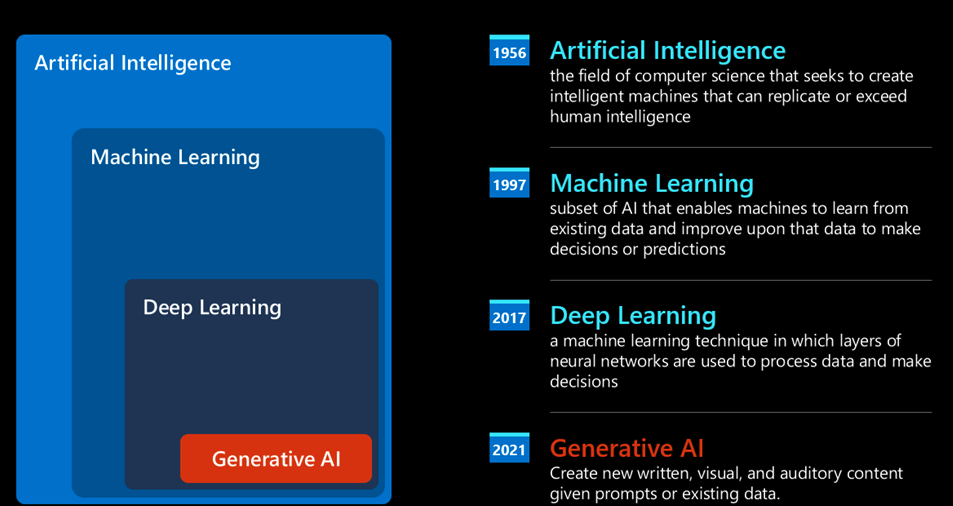
Để hiểu được mô hình ngôn ngữ lớn làm việc thế nào thì có rất nhiều bài viết và phức tạp. Dưới góc độ ứng dụng thì chúng ta có thể hiểu như sau:
- Tokenizer, text to numbers: Các mô hình ngôn ngữ lớn nhận một đoạn văn bản làm đầu vào và tạo ra một đoạn văn bản làm đầu ra. Tuy nhiên, vì là các mô hình thống kê, chúng hoạt sẽ hoạt động tốt với các con số so với các chuỗi văn bản. Đó là lý do tại sao mỗi đầu vào cho mô hình được xử lý bởi một bộ tách từ (tokenizer) trước khi được sử dụng bởi mô hình chính. Một token là một đoạn văn bản - bao gồm một số lượng ký tự thay đổi, vì vậy nhiệm vụ chính của bộ tách từ là chia đầu vào thành một mảng các token. Sau đó, mỗi token được ánh xạ với một chỉ số token, là mã hoá số nguyên của đoạn văn bản gốc.
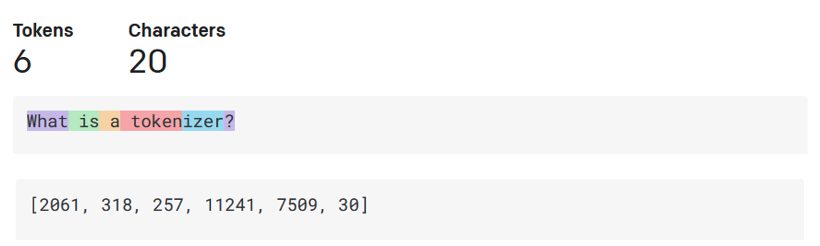
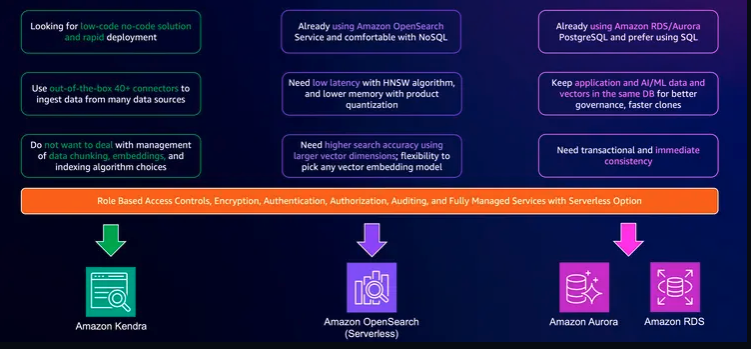
Đó là khái niệm Token, quay trở lại với hệ thống ChatBot và RAG thì thành phần quan trọng đó là VectorDB. VectorDB (Vector Database) là một cơ sở dữ liệu được thiết kế để lưu trữ, quản lý và tìm kiếm các vector. VectorDB chủ yếu được sử dụng trong các hệ thống học máy và trí tuệ nhân tạo, đặc biệt là trong các ứng dụng liên quan đến việc xử lý ngôn ngữ tự nhiên, hình ảnh, âm thanh và các dữ liệu phi cấu trúc khác. Các vector này thường là các biểu diễn số học của dữ liệu (embeddings), giúp các mô hình học máy có thể làm việc với dữ liệu một cách hiệu quả. AWS cung cấp rất nhiều tùy chọn hỗ trợ VectorDB khác nhau để các bạn có thể lựa chọn. VectorDB
Bạn có thể lựa chọn vectorDB theo những tiêu chí sau: Refer: vector-embeddings-and-rag
Để xây dựng hệ thống RA chúng ta có thể bắt đầu với kiến trúc như sau:
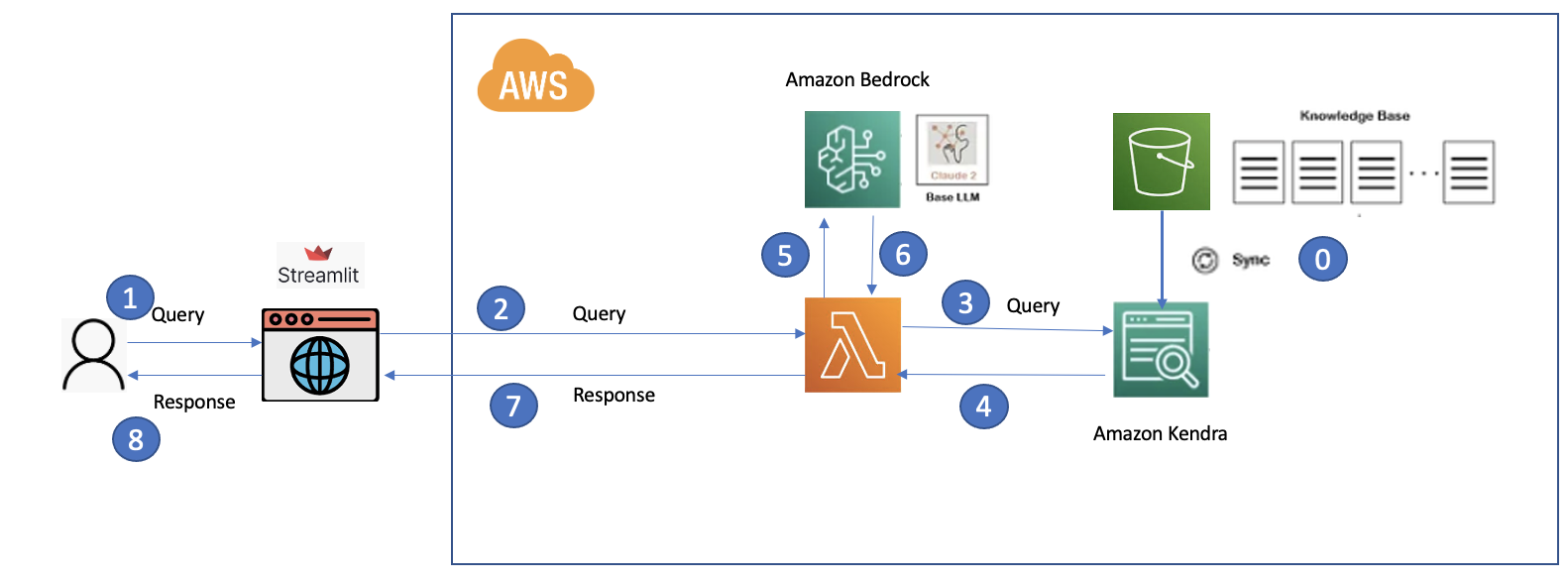
Trong kiến trúc này gồm các thành phần sau:
- Web UI: cung cấp giao diện cho phép người dùng tương tác vơi ChatBot. Ở đây tôi sử dụng Streamlit. UI sẽ invoke Lambda function để gửi/nhận request/response
- Lambda function: cung cấp api endpoint để Web UI có thể tương tác được với hệ thống.
- S3: lưu trữ document (Knowledge base)
- Amazon Kendar: index document cũng như search service trả ra dữ liệu liên quan tới câu hỏi từ người dùng.
- Amazon Bedrock: đây là một manged service cung cấp foudation model LLM.
Trong quá trình triển khai chúng ta sẽ sử dụng đến framework LangChain
Refer:
- https://aws.amazon.com/blogs/machine-learning/quickly-build-high-accuracy-generative-ai-applications-on-enterprise-data-using-amazon-kendra-langchain-and-large-language-models/
- https://medium.com/@zekaouinoureddine/how-to-build-high-accuracy-serverless-rag-using-amazon-bedrock-and-kendra-on-aws-9ec9681e4e9b